
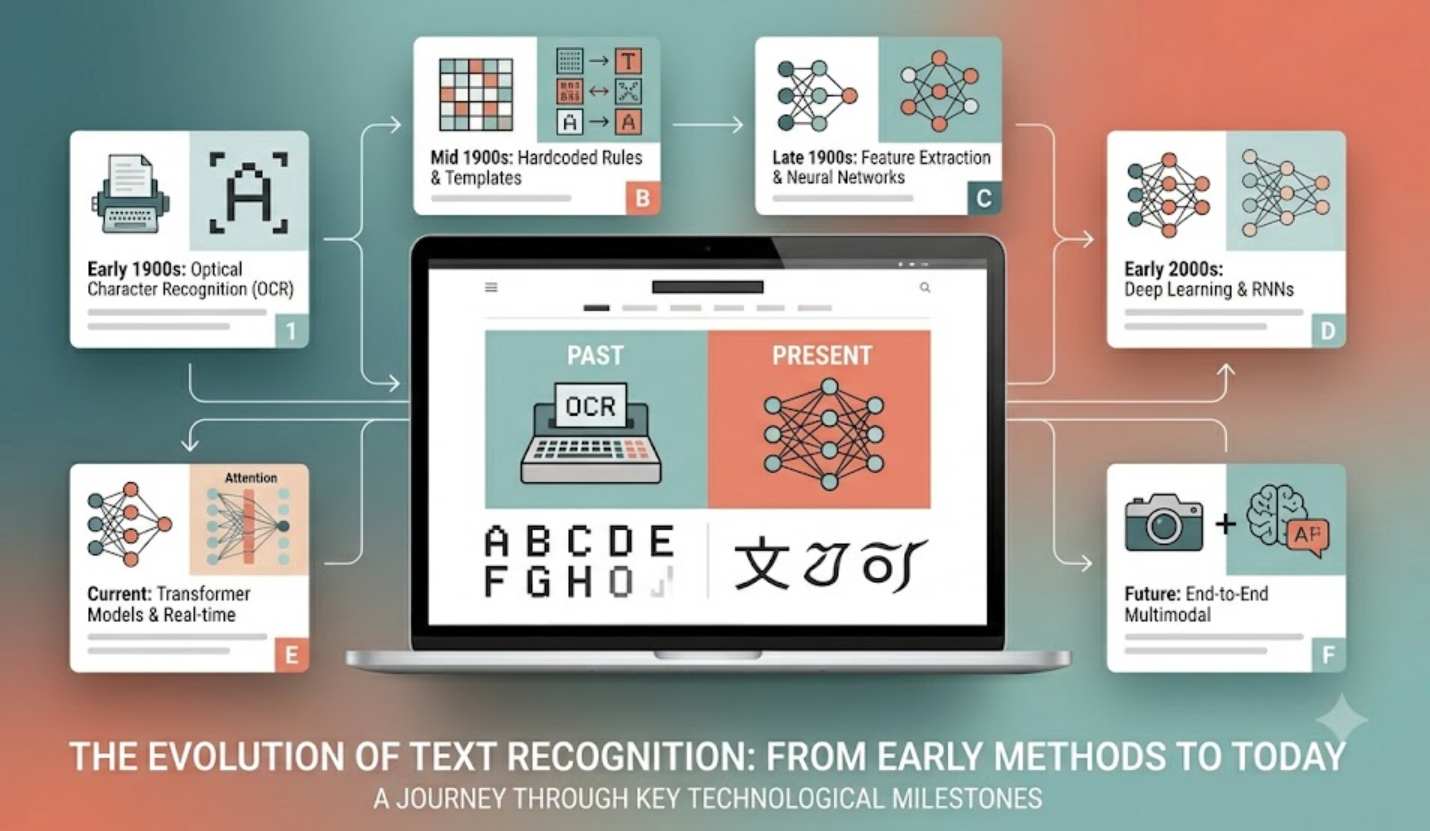
Have you ever scanned a document and watched it turn into editable text? It feels like magic. But this technology has a long and interesting history. Text recognition has come a long way since the early days of computing. Today, we use advanced software to convert printed text into digital data effortlessly. This article explores the journey of text recognition. You’ll learn how it began and how it works today. You’ll also discover its many applications.
The First Steps in Text Recognition
In the early days, text recognition relied on mechanical methods. Innovators used templates and electromechanical devices. These machines could detect characters based on their shape. The first devices were large and clumsy. But they laid the groundwork for future technology.
One notable early machine was the Edison memo printer. It used a mechanical approach to transcribe text from paper. Although primitive, this method opened up new possibilities. It showed that automating data entry was possible.
The Emergence of Optical Character Recognition
The 20th century brought a significant shift. The introduction of optical character recognition (OCR) marked a turning point. OCR made it possible to digitize printed text automatically. This reduced the need for human data entry.
OCR works by scanning a document and creating a digital image. The software then recognizes individual characters, words, and phrases. This was a revolutionary change. It made it easier for businesses to manage large volumes of paperwork. Suddenly, documents could be stored and searched electronically.
How OCR Works
The functioning of OCR involves several key steps. Each step is important for accurate text recognition.
Here are the main steps in the OCR process:
- Scanning the document into an image
- Cleaning up the image for clarity
- Recognizing characters and words
- Checking for accuracy and formatting
First, the document is scanned. A digital image is created. Next, the image is processed to enhance the text. Noise is removed and distortions are corrected. Then comes the core part. The software identifies shapes and converts them into text. Finally, the recognized text is checked for accuracy.
Modern OCR Technology
Today’s OCR technology is highly sophisticated. Modern systems use machine learning and neural networks. These improve accuracy in text recognition. They can handle many fonts, languages, and formats. A developer can integrate OCR Tesseract .NET into their applications to add powerful text recognition features. This makes text recognition more flexible than ever.
Innovations in deep learning have expanded OCR capabilities. It now works on complex documents like invoices and receipts. It can even read handwritten notes. This has broadened its applications.
Conclusion: Embrace the Evolution of Text Recognition
Text recognition technology has come a long way. From mechanical devices to AI-powered systems, it has transformed how we handle information. Businesses and individuals alike benefit from these advances.
Are you ready to harness the power of text recognition in your projects? Embracing these technologies can streamline your processes. It allows for more efficient handling of information. Join the conversation about this fascinating evolution. Become a part of the future of textual data management. For more insights, check out our other articles!